Guest post by David Churchward [Twitter]
Having hit the P&L and Cash Flow in previous posts, it seems only reasonable to move on to Balance Sheet aspects. The die-hard “non-accountant” Excel Pros and programmers amongst you are probably experiencing a sudden bout of Narcolepsy, but let me assure you that this gives us the perfect opportunity to explore dynamic banding in DAX so please prop those matchsticks in place for the minute!
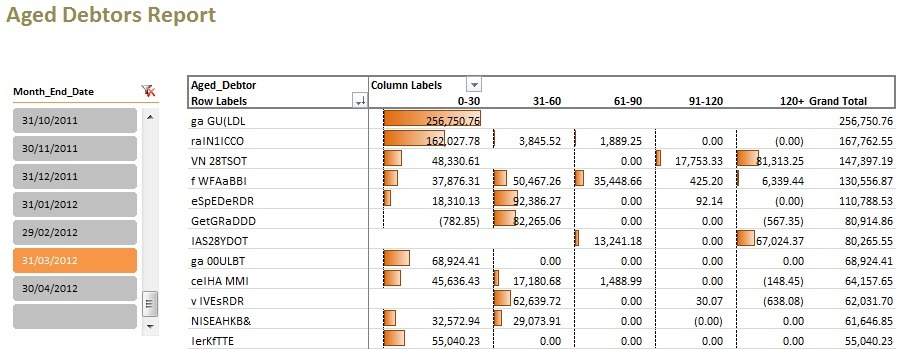
In this post, I’ll construct a dynamic Aged Debtors report. This will calculate debt ageing values, showing outstanding debts by customer at user defined points in time.
The Accounting Terminology Bit
Let’s get this done quickly. Debtors are those customers (normally) who owe the company money. This is often legitimate as it is normal to offer a customer a period of time to process your invoice and pay. However, it’s not unusual for this period to extend for a number of reasons. I won’t go into this now because I could waffle on too long with experiences in this area and I’ve never even worked in Credit Control!
In short, an aged debtor report details all outstanding debts, by customer, categorised into timeframe buckets to show how old the debt is.
Historically, it wasn’t unusual for an aged debtor report to be something that could only be run as at “now”. This means that accountants everywhere had a tiny window of opportunity to capture this information and preserve it in their archives with a wealth of information lost in hidden folders everywhere. PowerPivot gives us the opportunity to derive a report that holds all of this information with historical ageing available based on user selection and the ability to profile customers to see who tends to take their time to pay and maybe highlight some reasons why.
The Dataset
The transaction process probably looks something like this:
- Invoice is created at a point in time
- Payment is received from the customer and a payment transaction is created
- Payment is “allocated” to the invoice
Allocations Fact Table
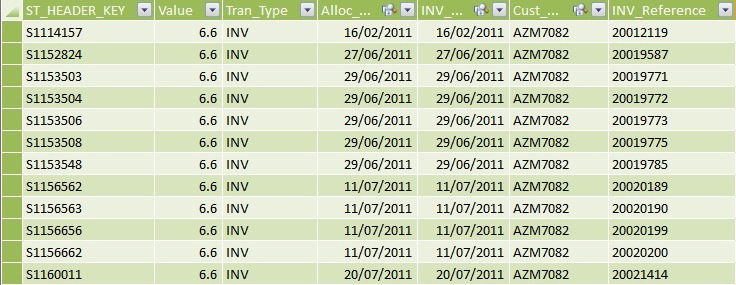
My core table here is an Allocations table. This table details all relevant transactions including invoices (and credit notes), payments and allocations. These transactions might look like this:

An invoice is raised for £10k on 15th March 2012 with an invoice reference (or invoice number if you like) of 1100.

Payment is received one month later with a reference of PAY1

The invoice and payment are allocated against each other meaning that the system has linked the payment PAY1 with the invoice 1100 and the outstanding debt is therefore zero and the payment is fully cleared down.
Customers Table
My customers table simply holds customer code and name, but it might hold other information about the customer such as customer contact and credit limit information. Unfortunately, I can’t display this table here as it holds real customer information and a scrambled name that I ultimately show on this report…sorry! (it sort of defeats the object if I give that away in a screenshot!!)
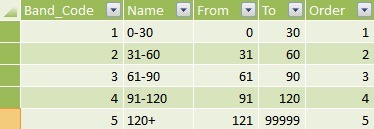
Bands Table
Outstanding debts need to be categorised into distinct bands. This is normally representative of months, but it can be anything. I’ve created a linked table in Excel which provides a Name together with From and To parameters. For example, 0-30 represents debts that are 0 (From) to 30 (To) days old.
Dates Tables
I use 2 dates tables. One is to link the allocation date to and the other is linked to the invoice date. I’m using V1 for this so I need both tables, but in V2 you can hold one dates table and then use the V2 function USERELATIONSHIP to determine which field to link through to the Dates table on.
These tables are simply a list of sequential dates covering the timeframe of my analysis. The invoice dates table holds an additional column called Month_End_Date simply to use as a logical slicer to put on my report.
Table Relationships
My relationships look like this:
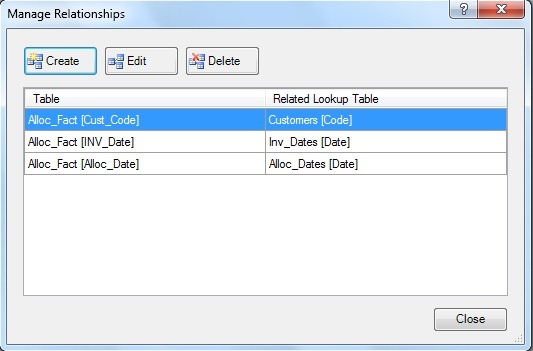
You’ll notice that the Alloc_Fact table links through to Customers and both of the Dates tables but there is NO relationship to Bands. Bands is a stand alone table that is used for report headings and parameters without any defined relationship.
Onto the DAX
My report is going to hold a slicer for Month_End_Date. This is an “effective” run date. That is to say that the user is going to select a time point up to which transactions and allocations will be included, but any transactions after those dates should be ignored.
Therefore, I create a measure called Debtor_Value which aggregates underlying transactions and allocations up to that date.
Debtor_Value
=CALCULATE(
SUM(Alloc_Fact[Value]),
FILTER(ALL(Alloc_Dates),
COUNTROWS
(
FILTER(Alloc_Dates,
EARLIER(Alloc_Dates[Month_End_Date])<=MAX(Alloc_Dates[Month_End_Date]))
)>0
)
)
This measure uses a FILTER() on the Alloc_Dates table using COUNTROWS() to specify those dates that fit a criteria of being prior to the date selected on the slicer.
Why use FILTER() and COUNTROWS()?
It’s a reasonable question to ask why I can’t use a simple Month_End_Date filter as opposed to using FILTER() and COUNTROWS(). I have to hold my hands up and put a call out to Rob and The Italians for a technical reason, but in my mind, I know that I’m using the same field (Month_End_Date) in the evaluation, once from the slicer and once from my row set. To define between the two, I need to use EARLIER() to reference my row set and MAX to call the value from my slicer. To do so, I have to use a filter context that creates a table expression to identify all of the dates that ARE to be used in my measure.
Incidentally, if you want more on EARLIER(), Rob’s Rat Analytics sums it up.
Thanks to Alberto Ferrari here as this filter expression is something I picked up from him on the Mr Excel forum.
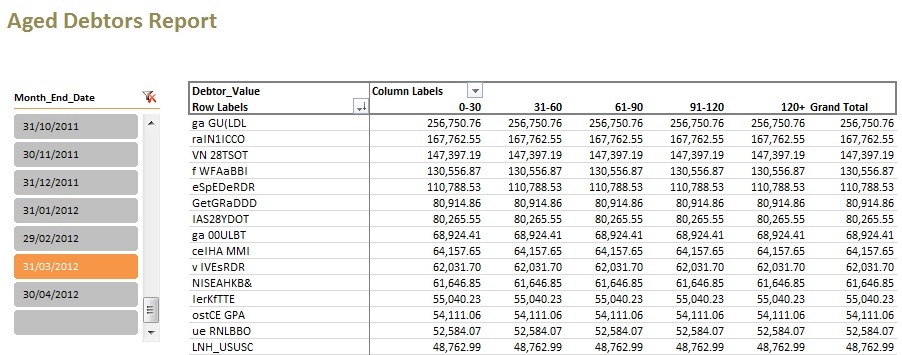
Irrespective of the technical explanation, I know that these values are correct, but the allocations to specific ageing buckets is obviously NOT.
Ageing Debtors
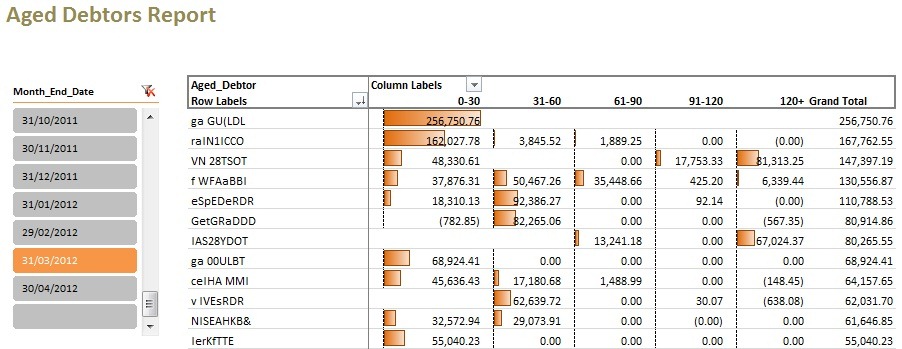
In order to allocate invoices to the correct ageing buckets, we need to calculate how old the invoice is and then calculate which bucket this relates to. The age of the invoice has to reference the selected Month_End_Date.
Aged_Debtor
=IF(COUNTROWS(Bands)=1,
CALCULATE([Debtor_Value],
FILTER(Inv_Dates,
MAXX(Inv_Dates,
MAX(Alloc_Dates[Month_End_Date])-EARLIER(Inv_Dates[Date])
)>=MAX(Bands[From])
&&MAXX(Inv_Dates,
MAX(Alloc_Dates[Month_End_Date])-EARLIER(Inv_Dates[Date])
)<=MAX(Bands[To])
)
),
[Debtor_Value]
)
The COUNTROWS() evaluation determines that we have one band to work with. This eliminates any confusion over the aggregation level that we’re working at and ensures that we will get one result for the FROM and TO elements of the band.
CALCULATE() then takes over to use our previous measure [Debtor_Value] within a filter context that determines the invoices (or rather invoice dates) to use.
The FILTER() element of this expression is where things get tricky. If I’m honest, in the first iteration of this measure, I tried to filter invoices. My rationale was that each invoice carried a specific date. From this date, I could determine how old the invoice was at any given point in time. And, you’ll be pleased to know that it worked. But there was a problem! Because I’m carrying over 300,000 invoices in my dataset (which isn’t actually that many), any SUMX or MAXX is going to iterate over 300,000 records and therefore may not be very quick. In addition, as my invoice count increases, so my performance is going to continue to degrade.
In an enlightened moment, I realised that I only had roughly 1,500 dates and the number of dates increases at a much slower rate than the number of invoices. Could I use the same approach purely on dates and ignore the invoice number? Ehhh………YES!
Essentially, MAXX is iterating over the table Inv_Dates and working out if the difference, in days, between the selected Month_End_Date on the slicer and Inv_Dates[Date] is greater than or equal to the Bands[From] AND also less than or equal to the Bands[To]. Where this is the case, this measure uses the value from [Debtor_Value] subject to the FILTER(). Where this is NOT the case, the measure uses the value from [Debtor_Value] but DOESN’T apply the FILTER() expression.
And, there you have it!
What’s Next
With these measures in place, wouldn’t it be great to mash this up with an invoicing profile and maybe even a dissection by product or industry sector to give a true profile on a customer? I’ll be back with a load of mashups on this as soon as I can.
Incidentally, as I alluded to earlier, this analysis is a real dataset so I unfortunately can’t release the Excel. Sorry.
Get in touch with a P3 team member