You asked for it and here it is! We’ve received a ton of buzz since introducing our March Data-Ness Machine Learning Data Model and we are bringing you all the details! There can be learning curves to just about anything and that includes machine learning. Our data model wasn’t exactly perfect, and we expected that because that is the nature of sports forecasting. But that’s okay because this was a learning moment both for the AI as well as for us sports fans. We have already had several upsets and can expect several more as the bracket proceeds. The ML model is still an outstanding piece of data engineering and, as the brackets continue, we are learning what types of tweaks can be used to perfect the process for next year. While we are working on our tweaks, though, we wanted to share the model creation process with you so you too can build your own machine learning tool!

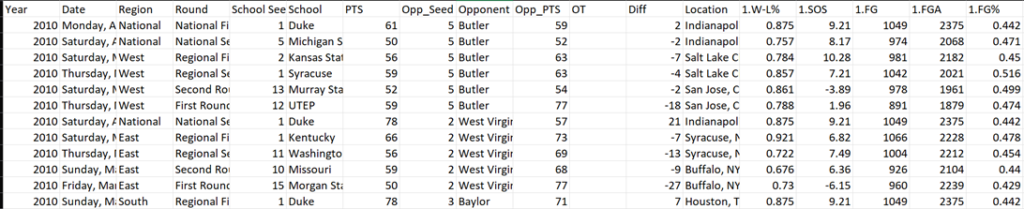
The first step in the machine learning process is gathering data. For this model, we used Power Query in Power BI Desktop to scrape historical NCAA Tournament matchups along with each team’s season statistics from the Sports-Reference.com website. This website had data back to 2010 which we exported to Excel as shown below. We pulled basketball statistics such as FG%, 3PT%, Strength of Schedule, Opponent Statistics, and more that will be used to predict the scores of matchups.
Side note, did you know that you can apply Machine Learning (ML) algorithms to your data in the Power BI Service using Dataflows? It makes Linear and/or Logistical Regression quite simple to use with a step-by-step GUI that gets you to a fully functional prediction model. The next steps discussed below, walk you through the rest of the process.
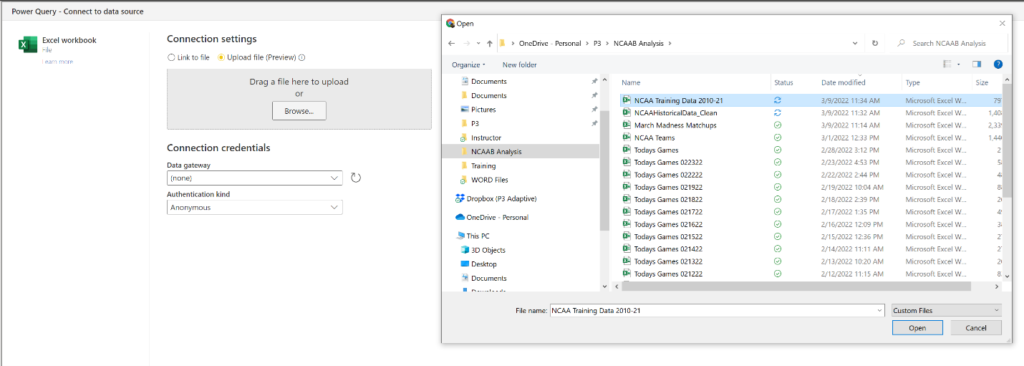
After the data is formatted, we upload it to a new Dataflow via Excel Workbook and use it to train a ML model on the data.
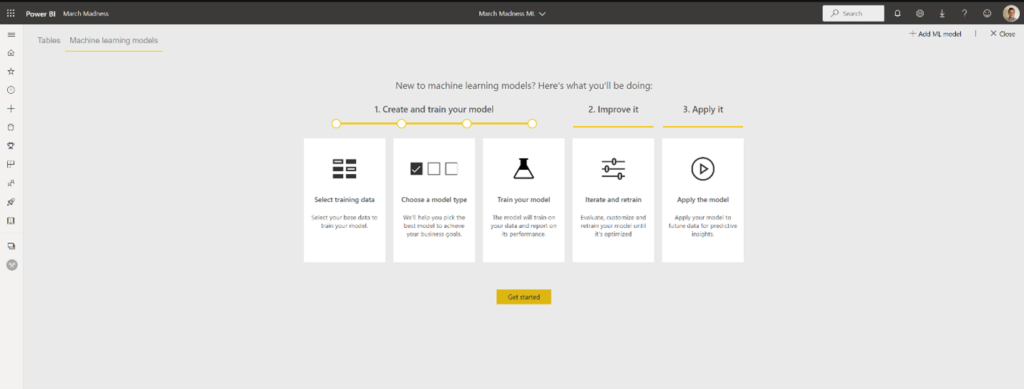
Within the Dataflow, we navigate over to Machine learning models to “Get Started”. The Get Started Wizard walks us through the process of training a ML model based on the data we uploaded.
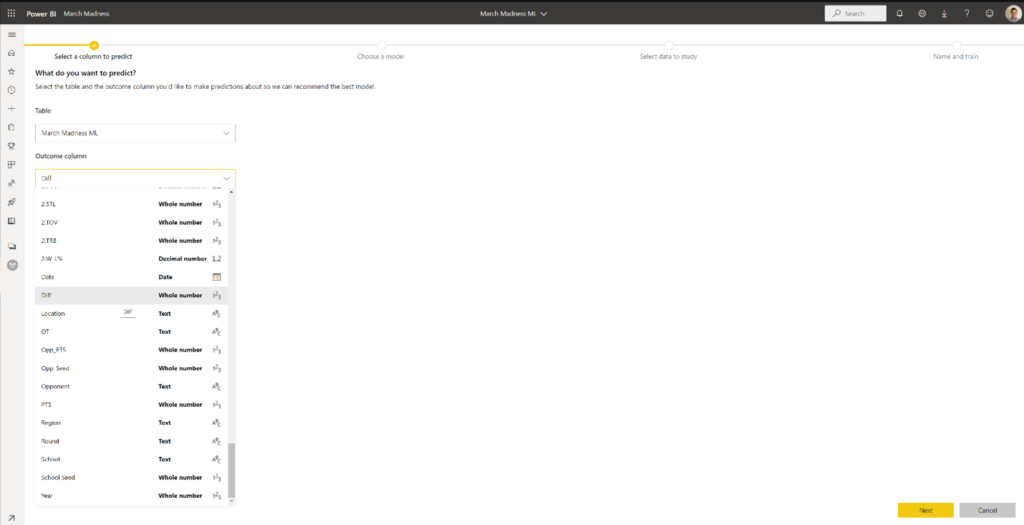
For this project, we will be using the March Madness ML table we created in Excel. The column labeled “Diff” is the difference in scores between Team 1 and Team 2. Since this column is an integer, Linear Regression will automatically be chosen.
We then select the factor columns from our dataset that we want to use as our independent variables. We select all columns below “Location” and ignore columns like “PTS” and “Opp_PTS” since these directly impact the “Diff” column which means we shouldn’t use it for predicting the outcomes of future matchups.
For this project, I choose an arbitrary 220 minutes to train the model. Power BI does all the heavy lifting for us including splitting your data 80/20 into training and testing sets respectively. That means you just have to save and hit “train” for the process to start.
Once training has completed, we have a functioning ML model to predict the scores of matchups based on season stats. Now it’s time to apply the model to the real data of the 2022 NCAA Tournament matchups so we can forecast upsets or verify which teams really are THAT good.
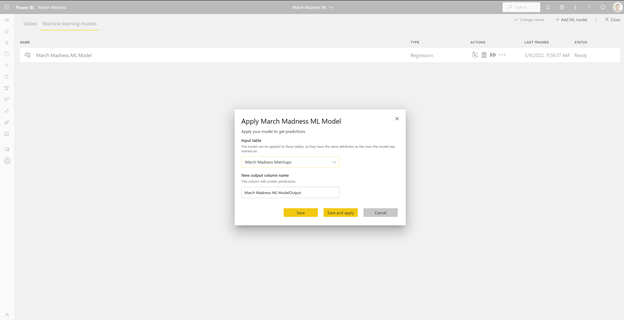
Now we upload the dataset we want to apply the ML model to and let it give us predicted scores. We use a similar process as before, but we create a hypothetical matchup of all 68 teams in the tournament along with their 2022 stats as the factors to use for prediction. We name this dataset March Madness Matchups. It’s important that we have the same fields available in this dataset as we had in our training set with the same column names.

From here, we simply navigate back to our Machine learning models and hit Apply ML model -> choose our “March Madness Matchups” dataset -> Save and apply.
Using the prediction score as the basis for our Power BI report, we built out a bracket that allows you to select winners while using the predicted score and other stats to inform your decisions! A positive predicted score means the team on top (better seed) is expected to win by that margin while a negative predicted score means the opposite, what we would call, an UPSET. You can also right-click and drill-through to the Matchup page to see more stats for both teams!
Now, you could take the approach of choosing whatever the model spits out, but a better way might be to look at similar matchups (i.e. 4 vs 13 matchup) and see which of those 4 have the lowest predicted score meaning the best chance of an upset. We use conditional formatting to highlight the games with similar seeded matchups. These are the ones with the best chance for an upset (darker blue meaning higher chance of an upset).
Check out the result here.
Do you think this was helpful as you filled out your bracket this year? Let us know in the comments!

Get in touch with a P3 team member