episode 169
Head to Head: Can ChatGPT Replicate Rob’s Inspired Solution to a Power Query Challenge?


episode 169
Head to Head: Can ChatGPT Replicate Rob’s Inspired Solution to a Power Query Challenge?
In this episode, Rob Collie and Justin Mannhardt step onto the data gridiron to test if AI can tackle the complexities of fantasy football data. Rob starts with a Power Query puzzle, full of messy stats, player names, and tricky injury codes—solving it manually in over 30 steps. But can ChatGPT, with Justin’s guidance, run the same play and simplify fantasy football data management?
Justin and ChatGPT take their shot at transforming the chaos into organized data. While ChatGPT makes some impressive moves, there are a few fumbles that leave us wondering—can AI truly handle the ever-changing landscape of fantasy football stats?
Want to know how this battle played out? Tune in to find out if AI has what it takes to streamline your fantasy football data or if human instincts still win the day.
Here is the companion Blog Post – Can AI Write an M Script When it Requires Inspiration? Rob Collie Squares Off Versus ChatGPT
See the code:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Episode Transcript
Rob Collie (00:00): Hello friends. In a recent series of podcasts, you've heard me describe my emerging view of what data projects are going to look like once Generative AI development tools reach widespread adoption, and in parallel what it's going to look like to be a data practitioner in that world. And the picture that's developing for me is that data practitioners are going to play the role, or roles, of composer, conductor, and editor. Today to use that same symphony analogy data practitioners play all of those roles already, but they also play like all of the instruments. Now, in the new world, data pros are going to sit at the intersection of business requirements, and things like Copilot, and ChatGPT. We're going to utilize those generative AI tools to generate code, script, formulas, and other logic much more quickly than we did before, but we're still going to need to understand both the original business problem, and the code being generated so that we can validate that it actually delivers on the needs that we had.
(01:05): Furthermore, we're going to need to be thinking logically, and clearly enough to instruct the AI tools in the first place. And quite frequently that's still going to require some human insight, and inspiration that isn't trivial. So, the emerging picture is that we'll still need the thing that I call the data gene, the population of people who are going to be willing, and able to play this AI composer, conductor editor role is basically the same population who's cranking out this kind of work today with one notable exception. The exception is this, the closer you are to being purely a developer, the closer you will be to being out of a job in the new world. If your job today is to take clearly written requirements, and translate those into code, well, that sounds a lot like what the Gen AI tools themselves are going to be doing.
(01:55): And by comparison, someone who is willing, and able to directly interface between vaguely expressed business needs on one side of the triangle, the Generative AI tools on the second side, and the actual runtime experiences like Power BI itself on the third side. Well, that person is going to be doing a multiple of the work that they were doing before, but in the same amount of time, and they're going to be much more effective in higher ROI than pure developers, so they're likely to gobble up your work. And to be honest, precisely expressed business requirements like in the form of a specification. Those have always been a myth, particularly in the data space. Humans just don't work that way, and that approach has always yielded low ROI, but I think Gen AI is coming to finally put the nail in that particular. So, to recap, pure developers are at risk, but we still need data geners, because the Gen AI tools are still going to require a mindset, and skill set that the average business stakeholder doesn't possess.
(02:57): As I've been saying, knowing what formula to write, and knowing how to verify that it's correct is far more important than knowing the syntax of how to write it. And I think the data gene crowd in particular, the kind of people we hire here at P3, well those first two things, those came first for us. We only learn the syntax, the third thing, because we knew what formula we needed, and that talent, knowing what formula you needed, what the logic is, that talent becomes even more valuable in the new world. But the Gen AI tools keep getting better. So, I'm keeping my eyes open to breakthroughs, which may change the story, which is where today's podcast comes in. I had recently written a power query script for a hobby project of mine, and I realized that there was a fair amount of quote-unquote knowing what formula to write, knowing what logic I needed involved in writing that script, and if the recent Gen AI tools were able to come up with that, the human inspiration, and insight that made me really important in that process, not just the syntax knowing.
(03:58): Well, I'd want to know that if the Gen AI tools were coming around to that. And who better to put ChatGPT through this exercise in this head-to-head competition against me than Justin himself who's utilizing these Gen AI tools all the time. So, can ChatGPT remove the need for the data gene human in the loop, or is my theory of data gene-er as conductor, composer, editor, still alive, and well? Is that still crucial? Let's find out a head-to-head power Query death match me against the machine with the fate of all humanity on the line, and seeing how there's a lot of stuff to look at here, the various steps, the prompts he gave to ChatGPT, the feedback he provided. We put together a bit of a companion blog post that you should pull up to. We're linking that in the show notes.
(04:44): I think it'll be really helpful for you to be looking at that kind of in parallel as you listen. Also, stay tuned at the end of the episode because after the dust settled here, I went back, and revisited my own script, and I was surprised by how different that felt already, how irreversibly changed I was by this exercise. All right, the gloves are off. Let's get into it.
Speaker 2 (05:09): Ladies, and gentlemen, may I have your attention, please?
Speaker 4 (05:14): This is the Raw Data by P3 Adaptive podcast with your host Rob Collie, and your co-host Justin Mannhardt. Find out what the experts at P3 Adaptive can do for your business. Just go to P3adaptive.com. Raw data by P3 Adaptive, down-to-earth, conversations about data tech, and biz Impact.
Rob Collie (05:44): Welcome back, Justin. I've been on kind of a roll with the solo podcast lately, but we have a real winner, I think, of a dual podcast idea today, and I'm really jazzed for it.
Justin Mannhardt (05:53): I am too. I do appreciate you taking the solo sessions. I've been busy with the real job stuff.
Rob Collie (06:00): Hey, I get it. Those last couple of solo pods are some of my favorite work that I've done in a while, so I'm equally grateful for the chance to monologue.
Justin Mannhardt (06:08): Love a good monologue.
Rob Collie (06:09): So, today, in a stunning turn of events, I called you in the morning, and said, "Hey, I'm thinking about what we talk about on the podcast today", and I had an idea. So, I have done something with Power BI that has no business value whatsoever. It's another use of technology for recreational means. It's one of my favorite things to do. I have been struggling with how much time, and effort, and energy fantasy football takes me.
Justin Mannhardt (06:34): I'm so sorry.
Rob Collie (06:35): I know. It's only the thing that I've been doing for close to 30 years now. After 30 years of fantasy football, I've experienced two firsts in the last week that have never happened as far as I can tell. Number one, I had one of my receivers on my team throw a touchdown pass to my quarterback.
Justin Mannhardt (06:51): That's nice.
Rob Collie (06:52): That happens every now, and then in the NFL, but never when they're both on the same fantasy team. That's kind of new. The other first is I have two players in my active lineup right now whose first name is Xavier. More importantly, one of my favorite things about fantasy football is trades, and this involves a lot of legwork. You've got to look at a lot of different web pages to look at other people's rosters, and you're constantly keeping things in your head. This person has X, Y, and Z, and they're weak here, and they're strong here, and maybe there's an opportunity there. So, then I have to go back, and look at my roster, and see if I actually have something I can put together.
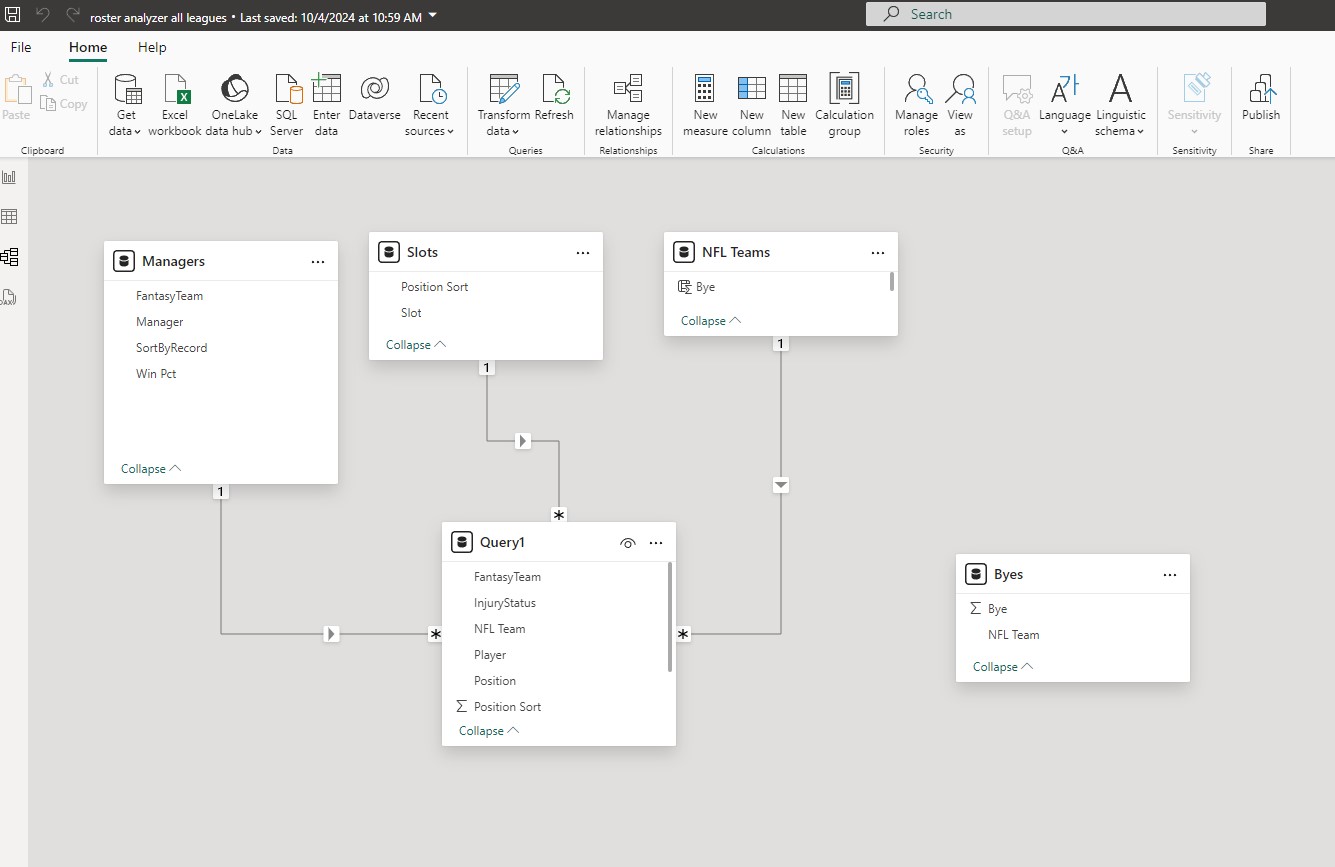
(07:22): There's all this context switching, and it starts to feel like when you're looking at many different reports, one from each silo, and you're having to do the math in your head to integrate the reports into a cohesive picture, whereas Power BI lets you join across them, and see one all-up picture. Well, in this case, I don't really need Power BI to do any analysis for me, but I do need it to make things much more convenient to look at. I want to just be able to click a slicer, and see people's lineups, not navigating web pages, alt tabbing, and trying to keep eight tabs open, and things like that. And this has already led to a couple of trades for me, and I've been keeping this secret. I've been keeping the existence of this roster analyzer.pbix, I've been keeping it a closely guarded secret until I realized that there's actually some compelling value here because in order to power this thing, I have to copy-paste one of the world's worst web pages as the data source.
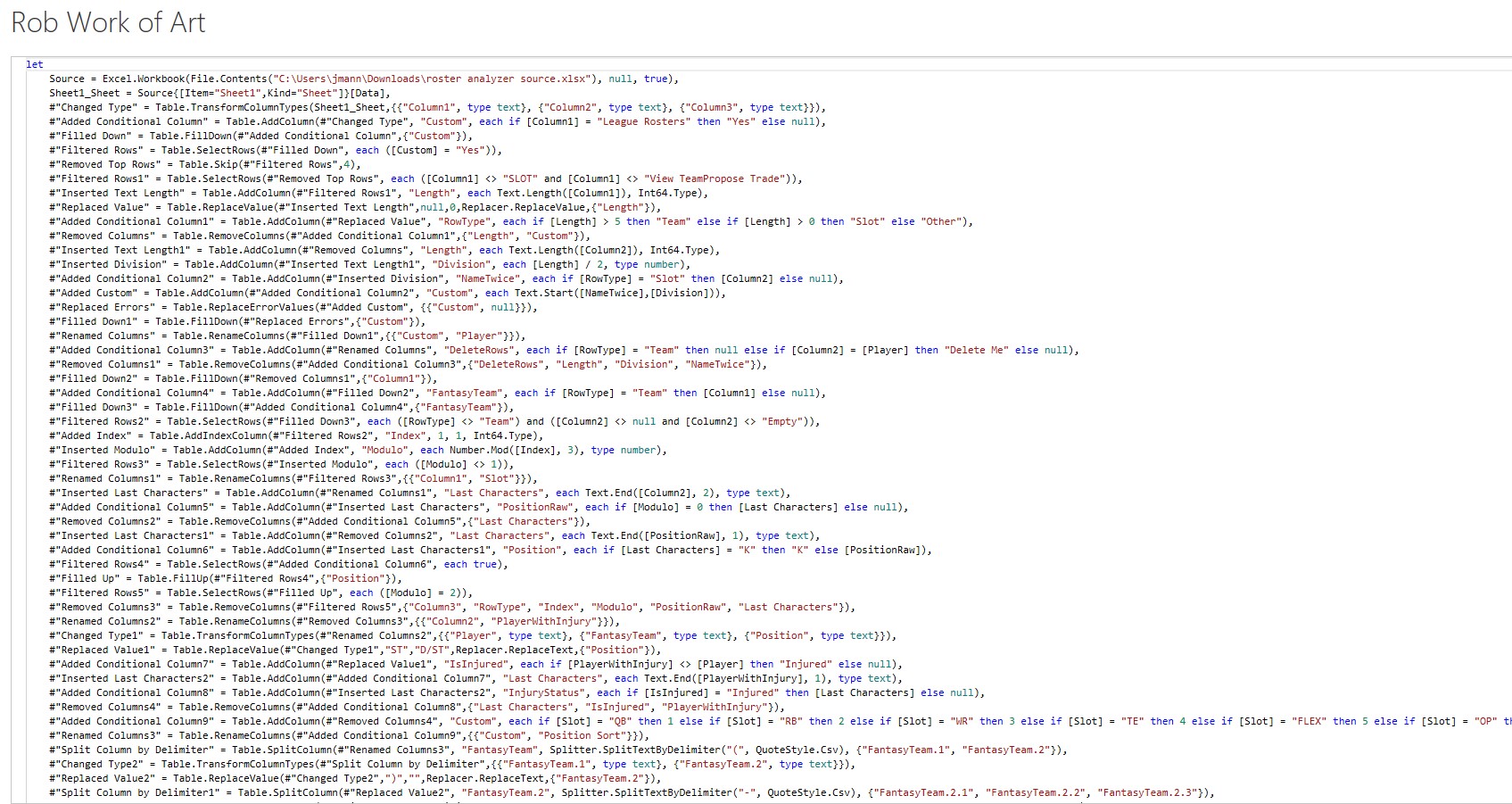
(08:16): And I mean this thing is loaded with banners, and all kinds of junk in it, and especially after the paste, there's just so much needless repetition that doesn't follow patterns reliably. It's just a nightmare. I've learned from my experience doing battle with the hockey scorers PDFs, I fight dirty. This is how I felt about my relationship with DAX, fighting dirty with Power Query, I love it. And I got a Power Query script written, an import script that processes this absolute mess of a webpage copy-paste that produces clean roster data for everyone in the league. There were so many steps where I needed to have some sort of inspiration in order to solve a problem. This is not linear A to B stuff. There's some art in what I had to write.
Justin Mannhardt (09:03): That's a great analogy.
Rob Collie (09:05): And I thought, "Oh, my God, if we can feed this to one of our Generative AI interfaces, one of the LLM overlords, and if it can do this, that would really, really, really surprise me, and impress me. But either way, no matter where it falls, no matter how well it does versus me, we're going to learn something because this is not just a straightforward layup." There's even really complicated things these tools can write, but they're still linear, and easy to specify, and this is not that at all. So, you've spent a good chunk of today sitting down with this problem, and saying, "Hey, ChatGPT what you got?"
Justin Mannhardt (09:42): That's right.
Rob Collie (09:43): I'm here to find out how well the AI has performed versus me.
Justin Mannhardt (09:49): First of all, this experience I've had today created all sorts of warm nostalgic memories for me because of what I used to do before I came to P3. I was running a team that we just got the ugliest of ugly data you could find. We had to clean it up, and we used Power Query to do that. When I saw your solution, it's a work of art, because it reminded me of the things we would do. And when you described art, I think that's right, because you have to figure out, "Okay, that piece of information is associated with that piece of information, but they're mismatched", because then you copy things into the wrong spots.
Rob Collie (10:28): And by the way, even copying the webpage, I've taken that philosophy. I just go to the webpage, and I do control A, select everything.
Justin Mannhardt (10:36): Control A.
Rob Collie (10:37): I don't want any variance in where my cursor was when I started to do the drag to select everything, control A, control C, flip over to Excel, and paste it, and then save that Excel file as the data source. Really, really bulk.
Justin Mannhardt (10:51): So, your solution, I didn't count, but I'm just looking at it now. I'm going to guess you've got 30 to 40 steps here, and you use the term brute force, or fighting dirty. I would always refer to this as someone's just sort of working in an inspired fashion through what needs to happen. I like art as the analogy here because I would always tell my team, imagine if you were a sculptor, and you had a tree stump, and you're going to carve it into a bear, or something, right? First you're going to start taking out the big hacks, and eventually you'll get more, and more refined, and you can see that in what you've done. You realize, "Oh, I can just filter out all these rows. I just don't need them." And then eventually you got somewhere.
(11:31): So, we're going to do a blog post, or link some of these assets in the show notes of the podcast so people can look at this while you're listening to the episode, and follow along, and understand what's going on, because I think the visual reference will help a lot. You kicked that over to me, and you said, okay, what can we do with ChatGPT. For context, I used ChatGPT 4.0, That's the model I used for this exercise, and let's get some of the big stuff out of the way first. So, I think you told me you probably spent about a half an hour working on this.
Rob Collie (12:02): I think it's about half an hour.
Justin Mannhardt (12:03): Okay, about half an hour. I think I ended up spending a little bit more time than that, more around like 45 minutes to an hour.
Rob Collie (12:10): Okay.
Justin Mannhardt (12:11): So, I definitely didn't do it faster than you. I ended up in a solution where ChatGPT gave me a complete set of code that did exactly what it needed to do, so I got to an end state that worked. I didn't have to go in, and tweak it. Now, I thought that I would end up doing that, and the reason I thought I would end up doing that is, well, number one, I'm good at Power Query. There was an error in my life where I would just write M code from scratch. I can't really do that anymore. I've lost that step, but I figured, "Oh, it's going to get me close enough", and then I'll sort of finish the job. But I realized once I started the process of engaging with ChatGPT said, "You know what? I'm actually not thinking about the code it's writing at all."
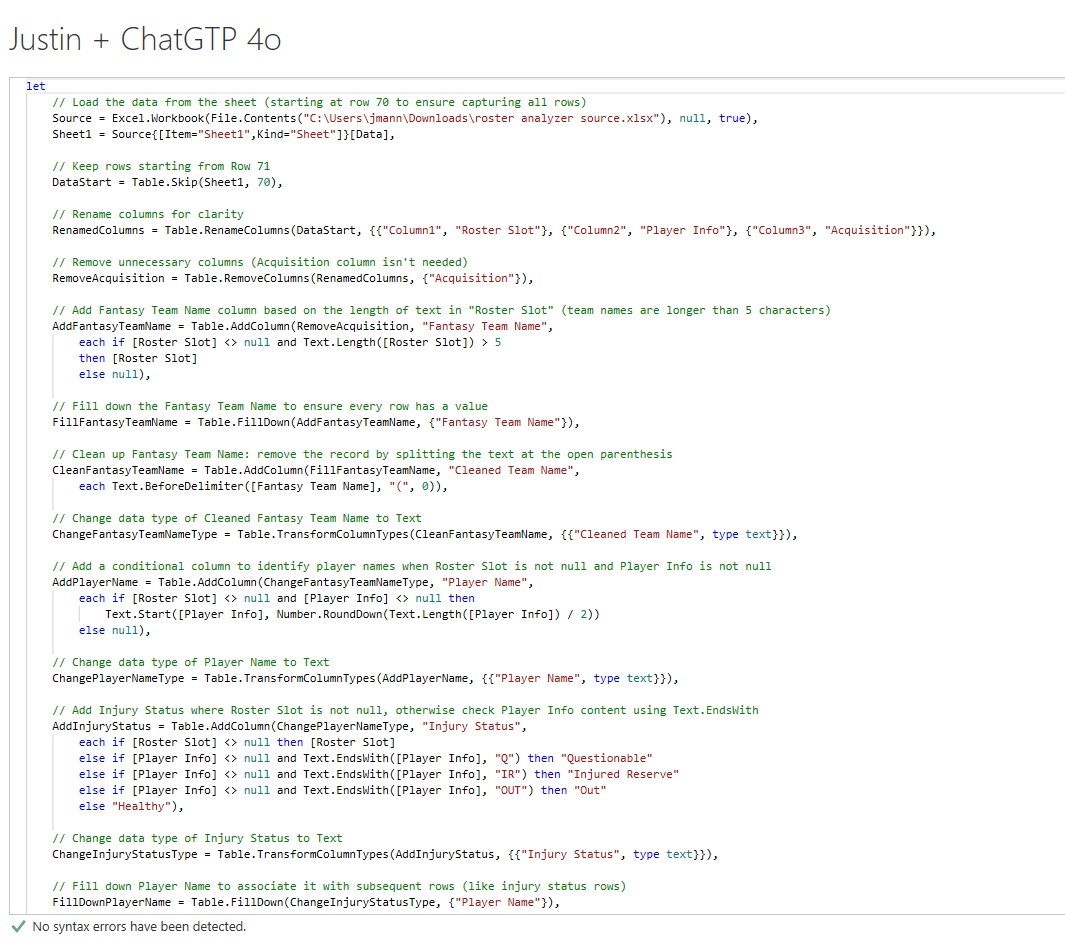
(12:52): I actually don't know when to slip in here, so I'm just going to keep telling you what's wrong about it, and asking it to fix it. Let me tell you what I thought was impressive, and let me tell you what I thought was maybe not so impressive. And then we can talk through that, and then let me tell you where I think the technology should go for it to be truly amazing. So, what I thought was impressive, the very first thing I did is I attached your source spreadsheet, so where you control A, control V from the website into an Excel file, I attached that spreadsheet to my prompt. We'll link the chat so you can go read through the whole chat.
Rob Collie (13:28): That's really important, folks. The chat transcript of Justin's back, and forth with ChatGPT is absolutely riveting.
Justin Mannhardt (13:37): Yeah, it was a neat experience. So, anyways, I just said, "Hey, here's this file, it's really messy. Here's where I need to end up." That was essentially my first prompt. And so it came back, and of course the first set of M code wasn't right, but the thing that it picked up on right away that I was not expecting is one of the columns in your final table is the injury status for the player. Are they active on the injured reserve? Are they questionable? Are they out?
Rob Collie (14:07): And by the way, this is really, really, really subtle because in the webpage version of this, if the player in question is injured, they will have a red Q next to their name. There's no space between the Q, and the name, but it's a different font, and it's a different color than the player name. It doesn't look like it's jammed in with the player name. However, when you copy paste, it'll be that player's name, and then a capital Q at the end without any space, without a delimiter. It just ends in Q. And there's other ones too ends in D. Now know that most player names aren't going to end in Q, but a lot of player names are going to end in D. So, it's just like, oh, it's so gross. So, continue.
Justin Mannhardt (14:45): And in the file, if you're listening, pause this episode, go download this stuff. I think that's a really interesting way to listen to this episode. So, for any given player in the copy paste source file, I think you had three rows per player effectively?
Rob Collie (15:00): Because it's HTML tables, right? The paste creates multiple rows when you really only see one row in the web page.
Justin Mannhardt (15:08): That's right. You needed to use the first row for their name, and then if they were injured, that little Q was in the second row. Again, I haven't told it how to do anything yet. I just said, "Here's the file, here's where I need to end up", and all I said is "I need a column for injury status." And it picked up on the fact that what it needed to do was look at the last set of characters in that column, and it understood that the specific sets of characters it should look for are the letters Q, the letters IR, and the letters O, and D for doubtful. Wow, that's really impressive. I have to assume it was some combination of A, I actually gave it the source data, and so it was able to sort of look at it so to speak, and it understood fantasy football.
Rob Collie (15:55): From its corpus of knowledge of the rest of the world has been fed to this thing before we showed up. It understands what the different injury designations are in the NFL. Unreal.
Justin Mannhardt (16:05): I thought that was clearly the most impressive thing that happened. The second most impressive thing that was like it got me to a correct answer, this is maybe a unique experience with me working with ChatGPT specifically on M code, where I never felt like we took a step backwards.
Rob Collie (16:22): Oh, okay.
Justin Mannhardt (16:23): Every prompt got better, and we sort of in a similar way, when you're just doing it with a UI, you didn't crack open the advanced editor to write code. You were doing point, and click the whole way. Similar how to you sort of brute forcing your way through the solution. I was doing the same thing. It kept getting better, and better, and better, and better, and better. It never took a step backwards, which I thought was impressive.
Rob Collie (16:43): I like at the very beginning how you explicitly gave it a personality. You told it who it was. This is you talking to ChatGPT. You are a data analyst who specializes in Power BI, and is specifically capable with Power Query, and M code.
Justin Mannhardt (16:57): I've just started doing that because of what other people have been saying over the recent months working with these tools, how telling the AI system what role you need it to play, giving it the right context, giving it instructions of how you want the output to come back to you. So, that's just like a habit I've built. I didn't do it without saying that, but it seems to be helpful.
Rob Collie (17:16): I bet sometimes it doesn't matter, but the times that it does, did it cost you much to write that extra sentence? Probably not. The other thing I want to just from your first prompt that I want to comment on is I wonder if there's another version of this experiment we want to run at some point. You're already kind of cheating on its behalf in the original prompt, you told it that the real data starts on line 71, and then I noticed in the M code that it just chops off the first 70 rows. That's the first thing it does in its M code. My M code is not going to hiccup if suddenly there's 72 lines of noise at the top. If ESPN adds another ad sign up now for fantasy hockey, which they're going to do, my control A, control C thing is not going to result in an error.
(17:59): It just took the shortcut of chopping off the first 70 rows. In the human versus machine war, I want to take every win that we've got here, and none of this is going to detract from how impressive this thing is. It's not, right. It is absolutely worth using, and I'm going to be referencing back to this chat session that you've had as sort of like a guide how I should approach it in the future. This is amazing, but the thing is you also said, "I suspect you will need to use conditional columns to extract information from column A to get these other things", right. A meta question I have for you is can we come back to this thing, and say, "Hey, forget all of that", the classic Mitch Hedberg joke. Forget everything you know about slip covers, so I did. Can we tell it to forget everything it's learned here from you so that we could have another clean test from a clean sheet where we gave it less to go on?
Justin Mannhardt (18:49): Yeah, I mean we could definitely just start a new chat session, and experiment with different ways.
Rob Collie (18:53): It doesn't leak though. One of the things that we've been learning, I think is how vague the boundaries are in what these systems learn, and what they preserve session to session.
Justin Mannhardt (19:02): Yeah. I'm not sure. I've sort of adopted an understanding that the right skill here is to assume you need to give it reasonable instruction.
Rob Collie (19:12): I completely get that. The way you approach this is the way that you would approach it if it were real. That's one of the reasons why I'm going to refer back to this chat session so much is because I'm going to be like, "Oh, Justin, if I can be like Justin", then there's the other part of me that's just insanely curious about what its capabilities really are, and that's a different lens. One of the things that throughout this session with it, it does make an occasional leap that just blows your mind like the injury status. But so many of the places where I had to come up with an artistic solution, I see throughout the chat you're giving it not the same hints, because as you went through the code with it took you to different places than my branching path did.
Justin Mannhardt (19:51): Which to be fair, for the record, I had Rob's solution going into this, so I kind of saw the path through the maze. Full disclosure.
Rob Collie (19:59): You didn't end up using the mod function. I mean, I'm very disappointed that I ran a mod on the row index.
Justin Mannhardt (20:07): I was like, "Why is he doing that? Oh, okay."
Rob Collie (20:09): Oh, yeah, see? Yeah. Yeah.
Justin Mannhardt (20:13): It's great. I thought about two tests I would be interested in doing as follow-ups here. One is just what you described. You're an expert. You can look at that spreadsheet, and you can figure out the artistic hoops we should try, and jump through to get to the solution. So, that's one test, give it less instruction, less hints. The other thing I thought about is what if I gave it a more comprehensive set of instructions from the jump? Again, I had the benefit of seeing the file, seeing your solution, but also know if I spent minutes just looking at that Excel file, I would have in my head sort of a plan of attack. And so I do wonder, "Okay, instead of me, what do I have here?" Maybe like 20 prompts throughout this exercise, or so? If I just give it a more comprehensive set of instructions...
Rob Collie (21:03): You give it the before data, the complete raw set, the paste from the web page. If we gave it a sample of what the output should look like in a separate Excel, I wonder how quickly it connects the dots.
Justin Mannhardt (21:14): Yeah, that'd be an interesting experiment, too. It'd even be fun, because I think we're going to either do an article, or we'll post the assets in the show notes. I mean, I'm sure there's a lot of interesting ways to go through this exercise. I'd be curious what people come up with.
Rob Collie (21:26): Quick question. If I went right now to the Power BI file that I have open, and I copy from the source table, the result table that comes out, the Power Query, and I just paste that into Excel, chop out most of the rows. So, it's just like three, or four sample rows at the top. Drop that sample file in Slack. Can you just do it?
Justin Mannhardt (21:44): Sure, yeah.
Rob Collie (21:45): Let's just do it. Let's just run that test like right now. So...
Justin Mannhardt (21:47): Oh, man, let's go.
Rob Collie (21:49): At Justin's inspiration, we're going to run a test where we sort of give it more context, and less context. So, we're going to give it fewer hints, but we're going to give it both the before, and the after. A sample, what like 10 rows that I just gave you
Justin Mannhardt (22:01): That's right.
Rob Collie (22:02): Of what the output data should look like. That's going to be worth a lot to the system. The idea here is we're going to see how many, if any, I'm expecting it to be multiple of the magic tricks that are required, like the inspiration that's required to pull this off. I'm expecting it to come up with some number of those on its own with this kind of prompt. The before, and the after. You're basically saying, "Hey, take this thing, the original prompts that you had, and turn it into something that looks like the following, and here's the sample."
Justin Mannhardt (22:32): So, here's what I've got. I'm going to stick with my best practice here. I'll say your Power BI data analyst with exceptional skill, and Power Query, and M code. Attached is the source data file titled roster analyzer source, and an example of the end result titled results sample. Write an M code script that achieves this data transformation. Fire in the hole.
Rob Collie (22:54): How close is the first jump?
Justin Mannhardt (22:56): It's analyzing.
Rob Collie (22:57): Yeah, chew on that. Hey, while we're waiting, remember the AI system that told you that my doctor uses? My wife, Jocelyn, she goes to the same practice but see's a different doctor, and I was in there with her today, and I asked her doctor, does he use that system? And he says yes. And he told me what it is, and it's Heidi AI, but he told me something really fascinating. He said, "It has a switch on it. It has two modes. You won't believe what they called the two modes. Left brain, and right brain mode."
Justin Mannhardt (23:24): Wow.
Rob Collie (23:25): Right. Yeah. And I think it's really clever, because the thing is we know that it's all GPU based, these LLMs, and everything, right? They are electronic digital intuition. They are right brain. You want left brain, that's CPU, so it's all right brain, but what they're really saying is it's a tuning of its sensitivity of confidence. The left brain mode says "Just the facts, ma'am. Only report the things as you've heard in the transcript that you, the AI system are 100% confident, are real, don't extrapolate." And the other one says, "Nah, run with it." But they named it really smart. They didn't name it as tight versus loose because no one would ever put it in loose mode, especially not doctors. They could have said, "Oh, sensitivity, where do you want the error bar set?" If they would've described it in a nerdy way, no one would ever use the good one. He is like, "Yeah, the right brain one's the only one worth anything. The left brain one's not any good." But the right brain one's magic. Really, really excellent feature naming. Excellent.
Justin Mannhardt (24:26): I agree. Are you ready?
Rob Collie (24:29): I'm ready.
Justin Mannhardt (24:30): It really fell down on this one.
Rob Collie (24:32): Did it?
Justin Mannhardt (24:32): It's awful.
Rob Collie (24:34): Oh, I'm so excited.
Justin Mannhardt (24:35): It's awful.
Rob Collie (24:36): I'm absolutely delighted.
Justin Mannhardt (24:38): Yeah, we'll share the chat, but it confirms how I've been thinking about things like these things are amazing, but they're not magic. Maybe someday the technology will advance to a point where you could do what we just did, but I think it actually confused it, because I'm reading the M code, and it just realized like, "Oh, what I should do is I'll remove the top four rows, and then rename the columns so they match the column names you gave me in the example."
Rob Collie (25:05): Wow.
Justin Mannhardt (25:06): That's actually a great confirmation, at least for me personally. You want good results from these things. It really is about your ability to give good instruction.
Rob Collie (25:15): To back up here, there are two kinds of change that these tools are going to be bringing to any sort of development work. Development work is just part of the consulting job. There's a lot more to it. I know that in the end, the output of our work product for our clients is some form of code, or logic in various forms, but when it comes to just hands-on keys, writing the scripts, the two kinds of disruption, or change here are number one acceleration. A friend of mine who recently was posting on Facebook about like, "Oh, my God, you have no idea ChatGPT is just the end of development." He's like, "You won't believe how good this is." And then I ask him if he's willing to come on the podcast, and he tells me, "I can't right now. I've been coding 12 to 15 hours a day for two weeks", and with no hint of irony, he had no idea how contradictory those two statements were.
(26:09): It's just so delicious. We have to have him on, and we are going to skewer him with his own words. It's going to be great. The other one is the idea that anyone can sit down, and get what they need. You can replace the need for people, what I call the data gene crowd whose brains are wired to think about these sorts of problems. Who can look at this gobbledygook, paste from the web page, and start to chew away at it even without AI to turn it into something good. Your first chat session with GPT reflected over, and over, and over again. You being that person, you being the data gene inspiration. The thing you wouldn't need to know is what buttons to press in the UI.
(26:50): You certainly wouldn't need to know how to write the M code, but it places a premium like we've been saying so many times so far, knowing what formula to write, knowing what logic is required, much, much, much more important than knowing how to author the syntax. And so, my thought was giving it the before, and after was that a lot of that data gene, or inspiration along the way that you did feed it wouldn't be necessary. Now, we also shouldn't take this before, and after test as like the definitive result.
Justin Mannhardt (27:19): Not at all.
Rob Collie (27:20): There are other models, right? Claude, et cetera. We should try those, and see how well they do, and the other thing is that they're going to get smarter. Just because it didn't succeed with this before, and after today, it might succeed, or get closer anyway with the before, and after tomorrow, but it's always good to know where that threshold is. This should be one of our ongoing benchmarks.
Justin Mannhardt (27:43): I love it.
Rob Collie (27:43): Every few months we hand it this challenge, and see...
Justin Mannhardt (27:45): The ESPN roster challenge.
Rob Collie (27:50): And just see how well it does. On related note, how annoying is it, and maybe you'll tell me that there's an answer to this. That ESPN website requires me to log in my browser before I can get to it, so I have this manual copy paste step that I have to perform because Power Query, as far as I know, doesn't log in. Can I get it to log in?
Justin Mannhardt (28:09): In some cases, but it's fancy footwork
Rob Collie (28:11): And the other thing is honestly, lately ESPN has been two-factoring me every time I sign in, and it signs me out like every 48 hours. This is not where the world's secrets are held. This isn't like someone's Bitcoin wallet. Why are you doing this to me?
Justin Mannhardt (28:25): Someone might pirate your Disney plus subscription, I guess, I don't know.
Rob Collie (28:29): Maybe, maybe. Or make a terrible fantasy football trade on my behalf. You never know. Don't worry. I can do that myself.
Justin Mannhardt (28:37): I can see someone doing that.
Rob Collie (28:38): And I now have a tool that accelerates the offering of bad trades.
Justin Mannhardt (28:42): There are a couple other things just worth honorable mention that I thought were really cool, and honestly valuable. One is the final code output was really nice.
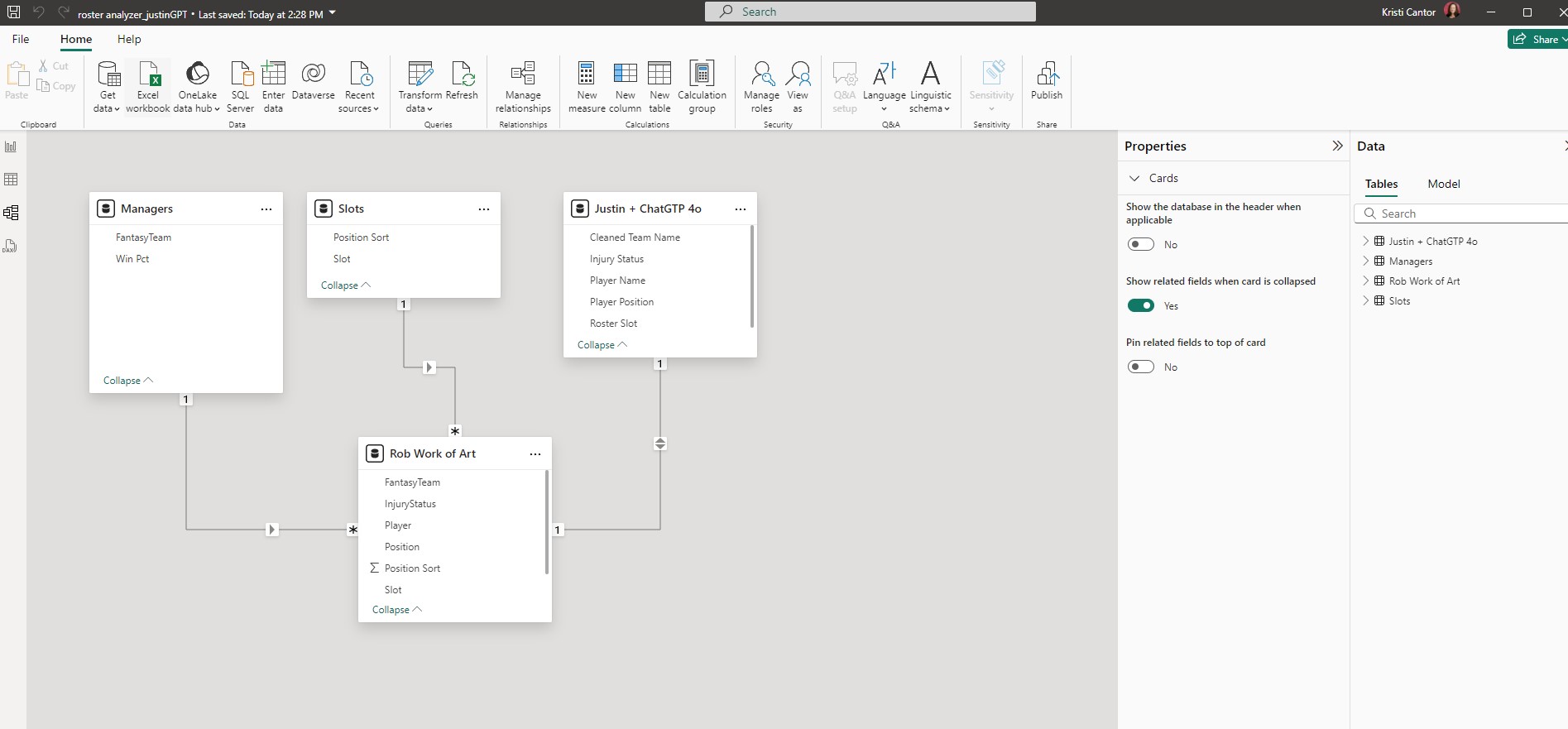
Rob Collie (28:53): Yeah, it's leaner than mine.
Justin Mannhardt (28:54): It's much leaner. I didn't ask it to, but it annotated all of the code.
Rob Collie (28:59): The steps, every single step of the Power Query, it renamed every step.
Justin Mannhardt (29:04): Yeah, everything has a good name. There's comments in the code, it explains what it's doing. That was really neat, and that's one of the drudgery things that basically nobody goes back, and does.
Rob Collie (29:16): It reminds me of named Ranges in Excel. We all know that named ranges make for better formulas that you can edit, and understand later, but the amount of effort that takes to go in, and eat your vegetables, and name all of your ranges just, oh, my God, great idea. So, tedious in execution. Same thing with my hockey scripts for importing the PDF files for the stats, and we're like into things like steps that are named, like rename columns 11. [inaudible 00:29:45] Oh, so you have no idea what's going on. Inserted custom column, great. What does that do? What was I after? It's just like that, the semantic intent, but yeah, you're right. The code that came out of ChatGPT, the steps are all named, and they're named beautifully.
Justin Mannhardt (30:02): And that's actually a really good use case that a lot of people are... They're not necessarily using AI to come up with the solution, but once they've got one, they say like, Hey, here's my code. Can you add comments to the code? Or, here's my complicated DAX function. Can you add the comments to it so people understand what it's doing?
Rob Collie (30:19): Steps called fill down player name. So, good.
Justin Mannhardt (30:23): Yeah.
Rob Collie (30:24): So, I can take existing M code, just wholesale copy, paste it out of the advanced editor, give it to ChatGPT, and say, "Hey, maybe give it some context."
Justin Mannhardt (30:32): Sure.
Rob Collie (30:33): And say, "Can you give this back to me in a more readable commented format?"
Justin Mannhardt (30:37): That's great.
Rob Collie (30:38): What a great idea.
Justin Mannhardt (30:39): The other thing, I didn't really realize this until I was close to done, and there could be bias going on here just because I did have a good time. This was fun to do, and it was neat, and we were excited about it. I didn't feel stressed out going through the process. I imagine you when you got to some of those trickier steps, just feeling your brain go, "What button do I need to click?"
Rob Collie (31:05): No, but I loved it. I loved every minute of that. It was a sense of sheer delight every time I turned a corner, and there was a new problem. You think you've got me now, but nope.
Justin Mannhardt (31:16): I guess the point I'm trying to make there is it was actually kind of a low stakes kind of a feeling. I think maybe only once, or twice did I use anything resembling telling it what function to use, or anything like that. It was just sort of explaining what was going on with the data, and I was like, "Hey, that's kind of neat."
Rob Collie (31:34): So, we don't want to get out of here without placing this in perspective, within the framework, and perspective that we've been developing here for ourselves, even at P3, the first thing is that are these LLM tools useful in some of these more hairy, or more custom, more inspired sorts of situations, and we know that they can just bang it out sometimes, the more linearly prescribed scenarios, they just do it. This was a deliberately selected challenge that's meant to be something it wouldn't be good at, and we're going to run into those problems all the time. You're still going to be running into those kinds of problems. The real world doesn't owe us clean, linearly prescribed problems all the time. Okay. Is it helpful in that scenario? The answer is yes.
Justin Mannhardt (32:18): Yeah, totally.
Rob Collie (32:19): If I had sat down with this, I was probably lying with 30 minutes. I don't know how long it took me. It might've been 90. I don't know, right? I was having so much fun doing it. If I'd sat down with it from the beginning, and been using it to help me do this, I probably would've got done sooner, but I also would've gotten a better result, maybe. I would've at least gotten commenting, and well-named steps, which is our kryptonite, it's just awful. So, number one, is it helpful? Number two, does it replace data geners at all? No. No, no. That is not the case here. You still need the metaphors I've been using. You need the songwriter, the conductor, and then changing metaphors a little bit, and a referee, like an editor that is validating the results, and giving sort of constructive feedback, which is the same sort of conversation you'd have with yourself if you were writing your own code, so it probably accelerates the creation of a solution.
(33:13): I didn't stop watch my original work session. I didn't realize we were going to do this until afterwards, right? It's been like two weeks. I've already been using this for a couple of weeks, so it's probably faster. It does produce a cleaner result. No two ways about it, and by the way, along the way, it also had at least one crazy out of left field inspiration to just pick up on injury status, but then in a subsequent test of like, "Here's before, here's after", which again, I kind of expected it to nail that it didn't.
Justin Mannhardt (33:41): Nope.
Rob Collie (33:42): It kind of reminds me a little bit of when you start doing column by example in Power Query, and it just starts coming up with the dumbest if, then, it's like, "No, you're totally missing the point." Silly column by example. It feels a little bit like that, what you described. It's like, "Here, we'll take what you gave us, and we will just crush it into this other package without any concept of what's in the box." I do suspect it's going to get better, and better stuff like that over time.
Justin Mannhardt (34:13): I agree. I was thinking about the experience, if I had any critique of this at this current state, it's that I need to possess an ability to understand what should happen to the data to get it from point A to point B. I certainly benefit from actually knowing M. Though, I could see a situation where that's not as necessary. That might be a fun experience. We go find someone that I don't know is like an Alteryx professional for an example. They get this stuff, but they don't do it in Power Query.
Rob Collie (34:43): I think they do very well here. It does make syntax just so much less important, the ability to change between environments, to change between coding environments, different tools. It's much more about having a brain that's wired, and experienced in certain ways.
Justin Mannhardt (35:00): My ability to troubleshoot was important when I realized, "Okay, it's not getting this tricky step quite right." I was back in Power BI. I had copy, and paste at its output, and I'd go through the steps, and realize, "Oh, it did this wrong."
Rob Collie (35:15): Yeah, that's the referee part.
Justin Mannhardt (35:17): That's the referee part, so that's both represents where the technology hasn't gotten to yet, as well as people that have this type of skill, you still absolutely needed in the future AI situation, which is important to remember right now.
Rob Collie (35:33): But you're probably going to move faster.
Justin Mannhardt (35:36): 100%.
Rob Collie (35:37): Think about all the different ways in which it's faster. The well-documented. Well-named steps means that a future version of yourself can come back to this, and pick it up. I really pity future version of me who hasn't played with the hockey model that I made for a long time. I mean, that thing is ugly, Justin. It's so ugly. Maybe I need to just start from scratch.
Justin Mannhardt (36:00): I didn't realize this until you were saying that, because it just did that naturally. It named the steps. Well, that became a shared language between me, and ChatGPT, because I could go back, and I could say, "Hey, your step named name, da-da-da-da-da-da, needs to be tweaked to do this." It actually made it easy for me to give it feedback now that I think about it, which is cool. Things that I would like to have done differently, or how I would rather this technology integrate with my workflow. We did the before, and after test. I think if I had to do this again, I would probably give it a more complete set of instructions from the jump. I went into it saying like, "Okay, I'm just going to solve one problem at a time." I kind of knew the tricks that we're going to need. I'd be curious what it would do if I just took the time to write that up all at once.
Rob Collie (36:49): I described this before as two different approaches to the experiment that we've run here today. One is you approaching it with your normal productivity hat on, and the other one was I was describing as for the scientific curiosity. Really, the second one though is how close, or far is it from replacing the data gener, the referee?
Justin Mannhardt (37:07): Yeah, not.
Rob Collie (37:08): You're saying, if I had to do it again, I'd give it more context, more information, et cetera. And that's doing a better job of being the productive version. The way that you've already learned to work with these tools. It's taking it further, and further from the other test, which is like if you just walk up to it naive, how far can it get you? And at the moment, not very far, and again, remember we didn't pick some crazy complicated Turing complete puzzle here. This is a real world example, but it happens to be a real world example that is just really kind of twisty. It's very pretzely, and the real world has problems like that, so.
Justin Mannhardt (37:45): Absolutely.
Rob Collie (37:46): It's a realistic example that's probably on the at, or above, the 90th percentile of difficulty. There are definitely people who use Power Query human beings who would look at this problem, and decide that it wasn't doable.
Justin Mannhardt (37:59): Agree.
Rob Collie (38:00): It takes a little bit of grease, and good old ingenuity to have gotten this done even as a human. It's not a layup.
Justin Mannhardt (38:08): No. The real thing I would hope for here, it would be really cool if this experience was in the product itself, and I think that's going to happen. It's just a matter of time, because I kind of committed to this idea that what I'm going to try, and do here in this experiment is get ChatGPT to produce a correct output all on its own, but there were certain steps where I could just click the UI, and do these first three things, and then I'd arrive at one of those puzzles, how to get the position, or how to get the injury status, or how to get the name to come out, and so at those points it'd be nice to be like, "Hey, I'm stuck here. Here's what I'm seeing in the data, and I'm not really sure what to do in the UI. I'm not really sure what code to write, help me."
(38:55): That I think is the next iteration of this. I do suspect that there's a future coming where the main interface, and our development tools is language, and maybe there's a ribbon that's there, and you can bring it out if you want it, but to be honest, for someone who hasn't written M code in a long time, it's a fairly enjoyable way to get through the solution. This is coming. These types of examples, they reinforce two things. One, the stuff is good, but number two, you still need the conductor, or the subject matter expert on the other end to do it.
Rob Collie (39:35): Yeah. At one point, backstage Luke was asking questions about like, "Ooh, what about the players whose last name does end in D? Did it mess those up?" We're like, "Well, that's a great question. We haven't checked." We went, and looked, and it found that it didn't mess them up. It would distinguish between the capital D, indicating doubtful, and the lower case D. What we're really getting at here, Luke, is that you're showing that data gene wiring, and that means that you could use this to write Power Query, no doubt about it. You don't even need to learn how to click the buttons.
(40:04): You just need to learn for the time being how to paste the ChatGPT code into the right spot in Power BI, so that's annoying having to constantly copy paste like that to evaluate it. That was one of the obstacles, and sort of the awkward things about using ChatGPT instead of something built into the product. The other thing is, yeah, you can't point to a particular step that you've kind of gotten to yourself, and say, "Just help me mess with this step." It's more like spitting you the code every time. Right? The whole thing. But the reason why we're using the external model ChatGPT, was it 4.0, is that what you said?
Justin Mannhardt (40:32): 4.0, yep.
Rob Collie (40:34): Is because that model is far more sophisticated than what is available inside the product today in the form of Copilot. ChatGPT stuff is racing out ahead in terms of its capabilities, and other commercial software is lagging behind in its integration of these newer, and newer models.
Justin Mannhardt (40:50): Yeah. I think I saw an article yesterday, or the day before that most of Copilot, Microsoft Copilot, I believe it was all based on GPT 3.5 plus. I have to fact check that with the Wave 2 announcements that Microsoft is bringing Copilot to GPT 4 across the board, which is previous to 4.0, which we were using today, which is previous to 0.1, which is Open AI, and Anthropic, and Meta. All these people that are out there innovating, and pushing these models, they're going to always be a few steps ahead of commercial software, and who knows how long that's going to play out, where there's that level of capability differential, and that's something to be mindful of right now.
Rob Collie (41:36): So, using ChatGPT 4.0 at the moment is really great preview of what capabilities will be coming to. It's an early warning system of what we should expect to see integrated more seamlessly into the products over time, but with some degree of lag.
Justin Mannhardt (41:53): Right? I'm using Gen AI tools on a daily basis constantly, and whether it's ChatGPT, Claude, Microsoft Copilot, I really encourage everyone just experiment. I didn't know going into this. I concluded one of two things. It's either going to fail miserably, I'm going to get frustrated, and I'm going to quit, or I'm going to get there. We've been joking about, "Well, how long did it really take you?" Even if we just assumed for the moment, it took us about the same amount of time, it's still pretty neat that it did what it did.
Rob Collie (42:29): I think you spotted a couple of more elegant approaches, like in the data gene sense to solving the problem. There were a couple of places where you used an if this equals that instead, and again, you didn't write that code. You just sort of told it what you thought it should look for, and I'm sitting there thinking, "Oh, man, maybe my mod, as much as I love it", because again, we end up with fewer steps in your approach. Again, with the asterisk that I think cheating a little bit with that chopping off the fixed number of rows at the beginning, can't wait for ESPN to change its artistic.
Justin Mannhardt (42:59): No, I'll come back around with another instruction, and be like, "Hey, I realized this isn't going to work." Yeah. I thought the if statements were really interesting too, I never explicitly told it, "You should consider an if statement." It's kind of a pain to set up if statements in Power Query, especially when you have more than a few.
Rob Collie (43:15): Oh, it's so bad.
Justin Mannhardt (43:17): Right?
Rob Collie (43:17): Zero stars. Do not recommend.
Justin Mannhardt (43:19): One of the main reasons I just started writing code from scratch because that UI experience blows.
Rob Collie (43:25): Yeah, it's so bad.
Justin Mannhardt (43:26): But that was good. I was like, "Oh, that's actually really smart. Yeah, just look for the right character strings here at the end of the", okay, yeah, right. Of course.
Rob Collie (43:33): That's exactly how I would've done it. All right, well, we solved that problem.
Justin Mannhardt (43:37): I think so.
Rob Collie (43:39): Okay, Rob, here again with the epilogue of the story. After growing through all that with Justin, I realized there was one small feature that I wanted to add to my original script. The first time around, I threw away a piece of information that was originally present in the copy paste of the web page, but I subsequently discovered that I wanted that preserved, and fed through as an additional column in my Power BI model. Now, if you're curious, the piece of information in question was the NFL team that each player plays for, but it's really going to not that important. So, I had a fork in the road right up front, start with my original script, or start with the one Justin had produced with ChatGPT. Well, it wasn't so straightforward because Justin had already skipped two kind of minor features that I had included in my script.
(44:23): Those features weren't important to the head-to-head competition at all, so it made sense for him to omit them, but back in my real world need, I need both. So, should I start with Justin's stuff, and add three features, or start with mine, and add one? Well, in my simple little brain, I compared three with one, and decided one was easier, so I went right back into my original script, and started manually modifying it in the Power Query interface. "It should take five minutes", I told myself. Famous last words. 45 minutes later I was still fighting with it. It turns out that those default name steps, the ones I was saying were such a big deal to have them clearly named versus named by default just a few minutes ago in the podcast? Well, they even worse in practice than I realized. It just so clumsy, and it became so clear how clumsy it was. Just so damn confusing, and difficult, for no good reason. And there were a few places where again, I had to go, and look up some annoying syntax, and then fight with it to get it to work.
(45:20): I would've been so much better off starting with Justin's script, like joining his chat session in progress with ChatGPT, and asking it to add that little feature for me. Heck, I would've been better off starting a brand new chat session with ChatGPT, giving it my existing script, asking it to clean it up, condensing redundant steps, renaming the steps to more meaningful names, and then going, and manually modifying it. But probably also just from there, just asking it to do it right, to add the extra stuff. I really need to get into this habit. It's still foreign to me. I suspect it's still foreign to a lot of you, but oh, my gosh, do we waste so much time screwing around with logic. Time really gets away from you. I'm now positive that my original script took me multiple hours, but I remembered it as 30 minutes, and I'm grateful to this fun little exercise for so viscerally demonstrating that to me. We can be so much more productive, and we owe it to ourselves, and to our stakeholders to change our workflows. Okay. That'll do it for this episode. Until next week.
Speaker 4 (46:20): Thanks for listening to The Raw Data by P3 Adaptive podcast. Let the experts at P3 Adaptive help your business. Just go to P3adaptive.com. Have a data day.
Sign up to receive email updates
Enter your name and email address below and I'll send you periodic updates about the podcast.
Subscribe on your favorite platform.